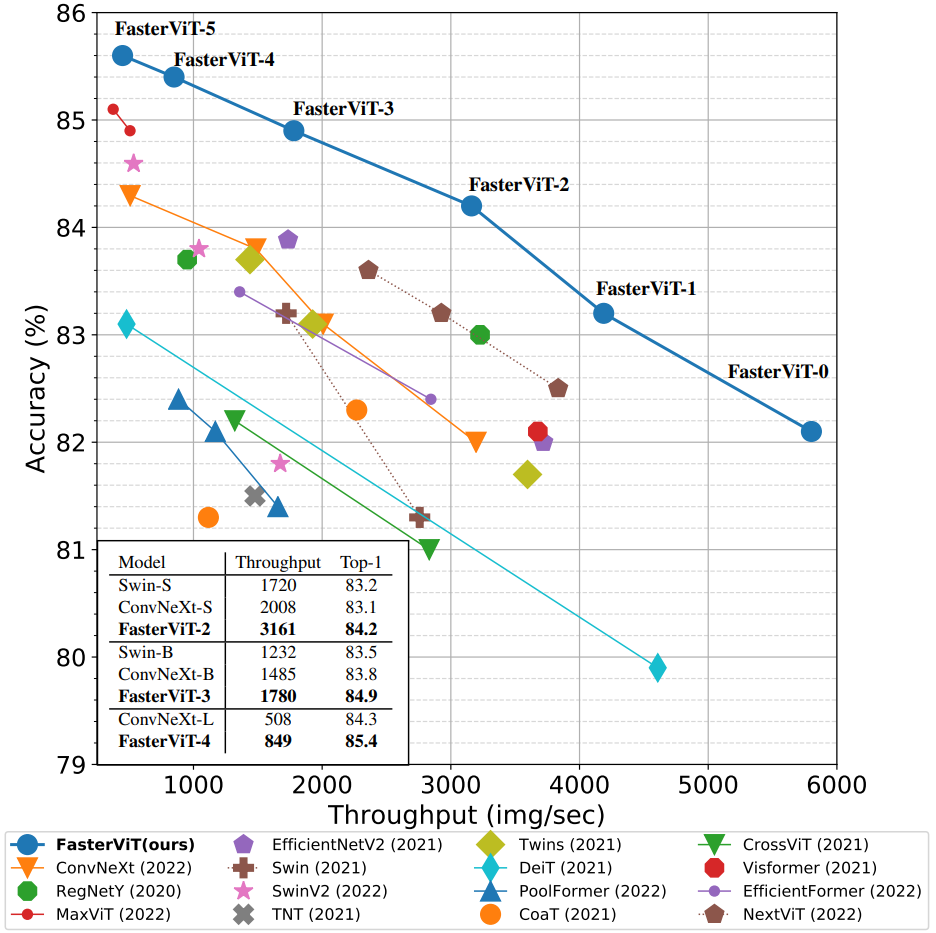
We design a new family of hybrid CNN-ViT neural networks, named FasterViT, with a focus on high image throughput for computer vision (CV) applications. FasterViT combines the benefits of fast local representation learning in CNNs and global modeling properties in ViT. Our newly introduced Hierarchical Attention (HAT) approach decomposes global self-attention with quadratic complexity into a multi-level attention with reduced computational costs. We benefit from efficient window-based self-attention. Each window has access to dedicated carrier tokens that participate in local and global representation learning. At a high level, global self-attentions enable efficient cross-window communication at lower costs. FasterViT achieves a SOTA Pareto-front in terms of accuracy vs. image throughput. We have extensively validated its effectiveness on various CV tasks including classification, object detection, and segmentation. We also show that HAT can be used as a plug-and-play module for existing networks and enhance them. We further demonstrate significantly faster and more accurate performance than competitive counterparts for high-resolution images. Code is available at https://github.com/NVlabs/FasterViT.
New hierarchical attention that facilitates local and global information exchange in a computationally efficient manner. The proposed hierarchical attention is shown in the following figure: