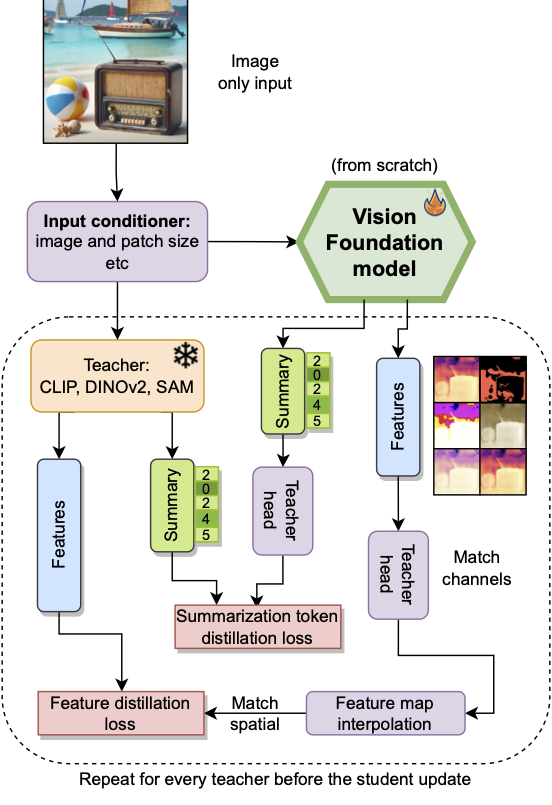
What is the best vision backbone for VLM? We saw that various backbones perform differently at specific tasks. You should use them all! We study on how to distill large vision models together to beat them. Large improvements in LLaVa-1.5. Main findings: (1) Distillation helps with any number of teachers, we use: CLIP, DINOv2, SAM; (2) Distilling feature maps is very important; (3) there are multiple challenges in image resolution, different batch-size and parallelization with multiple teachers. (4) we can beat all teachers if use a strong ViT backbone; (5) analysis on using efficient vision backbones showed - many are tuned too much for ImageNet and dont scale to infinite data; (6) We propose a new architecture (E-RADIO), that dominates latency-acc and is 10x faster. (7) SAM is not good if used out of the box, gives great edges but poor description of objects; (8) DINOv2 performs much better in VLM tasks; (9) our model requires only 2-5% of data with no labels comp to CLIP.