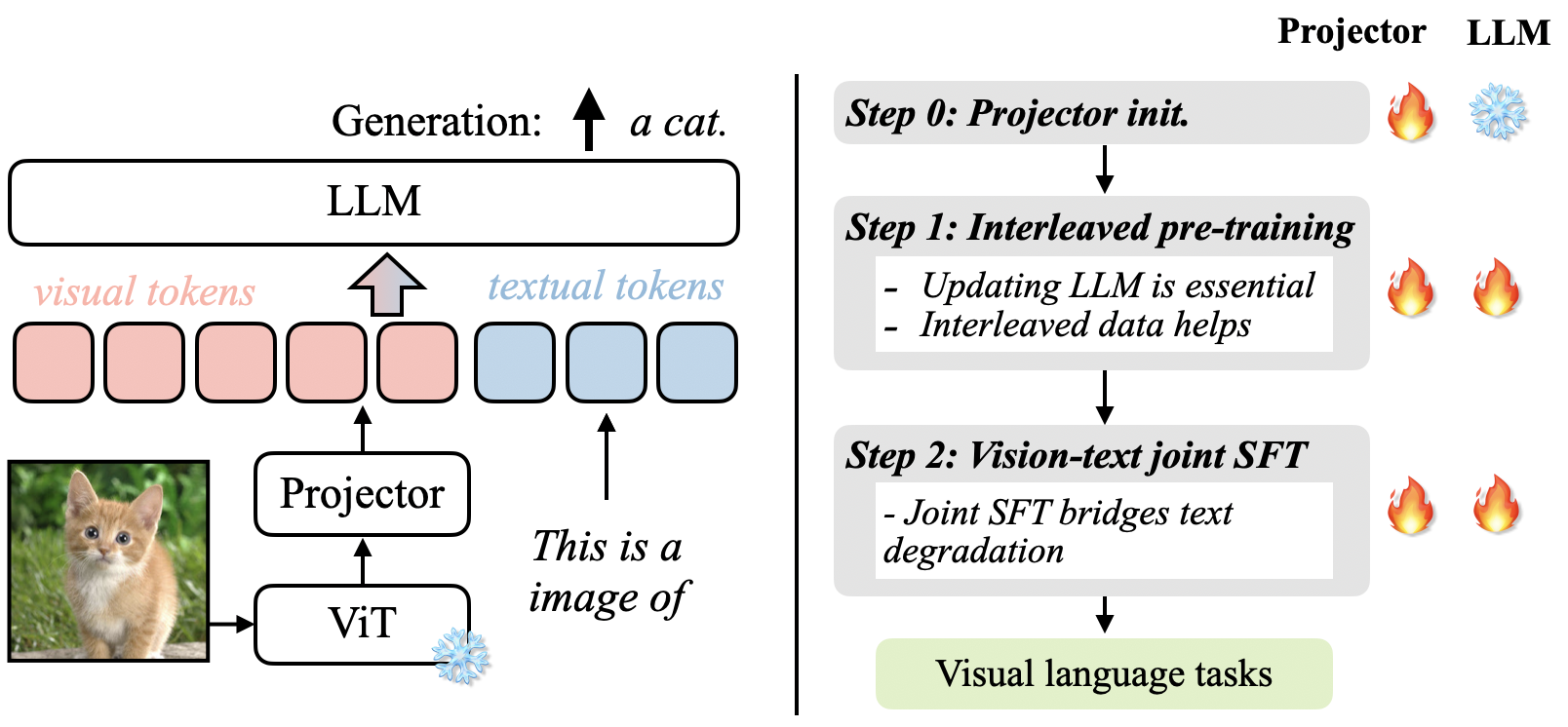
Findings: (1) after feature alignment, unfreeze LLM for pre-taining, this will improve in-context learning ; (2) interleaved pre-training data is beneficial, or text-only accuracy degrades by 17.2%; (3) Image-text pairs alone are not optimal, use MMC4; (4) re-blending text-only instruction data to image-text data during instruction fine-tuning not only remedies the degradation of text-only tasks, but also boosts VLM task accuracy.